



排序

讓MySQL數據庫跑的更快 為數據減肥
在MySQL數據庫優化工作中,使數據盡可能的小,使表在硬盤上占據的空間盡可能的小,這是最常用、也是最有效的手段之一。 在數據庫優化工作中,使數據盡可能的小,使表在硬盤上占據的空間盡可能的...
DB2中兩種語言:SQL/XML和XQuery的使用
DB2 9 引入了 pureXML 支持,這意味著 XML 數據是以其自身固有的分層格式進行存儲和查詢的。為了查詢 XML 數據,DB2 提供了兩種語言:SQL/XML 和 XQuery。 您可以單獨使用 xquery 和 sql,但也...

詳解SQL Server 2008 R2數據挖掘外接程序功能
SQL Server 2008 R2向前端工具開放了數據挖掘能力,通過集成在Excel中的插件,允許用戶連接到SQL Server服務器,直接操作多種數據挖掘算法,解決日常應用中的小型預測問題;使用過程中,用戶幾乎...
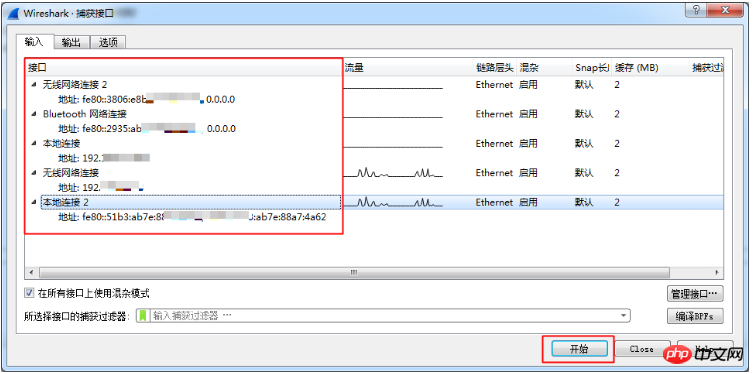
源服務器訪問目標服務器時出現異常如何抓包獲取最原始的交互數據
本篇文章給大家帶來的內容是關于源服務器訪問目標服務器時出現異常如何抓包獲取最原始的交互數據,有一定的參考價值,有需要的朋友可以參考一下,希望對你有所幫助。 網絡異常時抓包操作說明 如...

apache hadoop怎么讀
apache hadoop(讀音:[??p?t?i][h?du:p])是一套用于在由通用硬件構建的大型集群上運行應用程序的框架。它實現了map/reduce編程范型,計算任務會被分割成小塊(多次)運行在不同的節點上...

什么是apache kafka數據采集
什么是apache kafka數據采集? Apache Kafka - 介紹 Apache Kafka起源于LinkedIn,后來成為2011年的開源Apache項目,然后在2012年成為Apache的一流項目。Kafka以Scala和Java編寫。Apache Kafka...

apache hadoop是什么意思
apache hadoop是一套用于在由通用硬件構建的大型集群上運行應用程序的框架。它實現了map/reduce編程范型,計算任務會被分割成小塊(多次)運行在不同的節點上。除此之外,它還提供了一款分布式...

apache spark 是什么
Spark是一個基于內存計算的開源的集群計算系統,目的是讓數據分析更加快速。Spark非常小巧玲瓏,由加州伯克利大學AMP實驗室的Matei為主的小團隊所開發。使用的語言是Scala,項目的core部分的代...