



排序

Python爬取數據存入MySQL的方法是什么
本文將詳細介紹如何使用Python從網絡中獲取數據并將其存儲到MySQL數據庫中。希望通過本文的分享,能為大家提供有用的參考,幫助大家在數據處理方面有所收獲。 Python爬取數據并存儲到MySQL數據...

Python中如何遍歷DOM樹?
在python中,遍歷dom樹是為了解析和操作文檔元素。使用beautifulsoup庫,可以通過遞歸或迭代方法遍歷dom樹:1)遞歸方法直觀但可能導致棧溢出;2)迭代方法高效,避免棧溢出。完整句子結束。 在Py...

Python中如何模擬瀏覽器操作?
在python中模擬瀏覽器操作主要使用selenium和beautifulsoup。1.安裝selenium:pip install selenium。2.選擇并配置瀏覽器驅動程序,如chromedriver。3.使用selenium啟動瀏覽器并訪問網頁。4.模...

python爬蟲需要學哪些東西 爬蟲必備知識清單
要成為python爬蟲高手,你需要掌握以下關鍵技能和知識:1. python基礎,包括基本語法、數據結構、文件操作;2. 網絡知識,如http協議、html、css;3. 數據解析,使用beautifulsoup、lxml等庫;4...

python永久免費版入口 python免費版看電影入口地址
Python,作為一門廣泛應用于科學計算、數據分析、機器學習等領域的編程語言,其開源特性使得它在全球范圍內備受歡迎。然而,Python不僅是程序員的得力工具,它還可以為影視愛好者提供一個全新的...

Python中怎樣實現Web爬蟲?
用python實現web爬蟲可以通過以下步驟:1. 使用requests庫發送http請求獲取網頁內容。2. 利用beautifulsoup或lxml解析html提取信息。3. 借助scrapy框架實現更復雜的爬蟲任務,包括分布式爬蟲和...

Python中如何解析HTML文檔?
在python中高效解析html文檔可以使用beautifulsoup和lxml庫。1) beautifulsoup適用于處理不規范的html,提供簡單導航和搜索功能,但解析速度較慢。2) lxml解析速度快,支持xpath查詢,但對不規...

Python中怎樣解析HTML文檔?
在python中解析html文檔可以使用beautifulsoup、lxml和html.parser等庫。1. beautifulsoup適合初學者,易用但處理大文檔較慢。2. lxml速度快,適合大規模數據,學習曲線較陡。3. 遇到不規范html...

如何在Python中使用BeautifulSoup?
使用beautifulsoup解析html和xml文檔的步驟如下:1. 安裝beautifulsoup:使用命令“pip install beautifulsoup4”。2. 導入beautifulsoup:在代碼中使用“from bs4 import beautifulsoup”。3. ...

怎樣用Python爬取網頁數據?
python是爬取網頁數據的首選工具。使用requests和beautifulsoup庫可以輕松發送http請求和解析html內容。1)發送http請求:使用requests庫獲取網頁內容。2)解析html:使用beautifulsoup庫提取數...
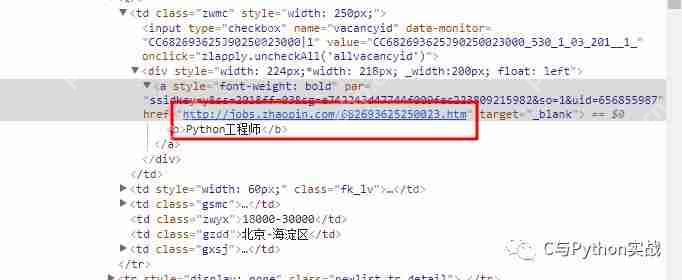
Python爬蟲之六:智聯招聘進階版
運行平臺: windows python版本: python3.6 ide: sublime text 其他工具: chrome瀏覽器0、寫在前面的話本文是基于基礎版上做的修改,如果沒有閱讀基礎版,請移步 Python爬蟲之五:抓取智聯招...