



排序

聊聊laravel中報錯日志的位置
laravel 是一個底層架構優良、易于擴展的 php web 開發框架,被廣泛應用于各類 web 應用的開發。但在使用 laravel 進行開發時,不可避免地會遇到各種報錯,在排錯過程中,日志文件是重要的參考...

Kafka在Linux上的擴展性如何實現
Kafka在Linux環境下的擴展性,核心在于增加Broker節點,并借助ZooKeeper實現集群管理與協調。本文將詳細闡述Kafka的Linux擴展方案。 Kafka集群擴展方法 新增Broker節點: 在Linux集群中添加新的B...

FetchLinux在大數據處理中的應用場景
alt='fetchlinux在大數據處理中的應用場景' /> 根據搜索結果,我沒有找到FetchLinux在大數據處理中的應用場景,但是我可以為您提供Linux在大數據處理中的應用場景: 大數據處理框架 Hadoop:...

Linux Kafka數據備份與恢復方法
本文介紹在Linux系統中備份和恢復Kafka數據的幾種方法。 方法一:使用Kafka自帶工具 Kafka-dump (導出全量數據) 安裝:使用系統包管理器安裝,例如在Debian系統中:sudo apt-get install kafka-...
如何調整Ubuntu Kafka的內存設置
調整ubuntu kafka的內存設置主要涉及兩個方面:調整jvm堆內存大小和優化kafka配置文件。以下是具體的步驟和建議: 調整JVM堆內存大小 Kafka運行在Java虛擬機(JVM)上,因此首先需要調整JVM的堆內...
Debian文件系統兼容性如何測試
若想對Debian文件系統的兼容性展開測試,您可以按照如下步驟操作: 前期準備: 確保擁有多種版本的Debian安裝鏡像,比如Debian 12.9.0。 準備好用于測試的設備,如樹莓派或者其他能夠運行Debian...

Linux HDFS如何實現實時數據處理
Hadoop分布式文件系統(HDFS)本身并不是為實時數據處理設計的,它更適合于批量處理和存儲大規模數據集。然而,可以通過結合其他工具和框架來實現實時數據處理。以下是幾種常見的方法: 結合Apa...
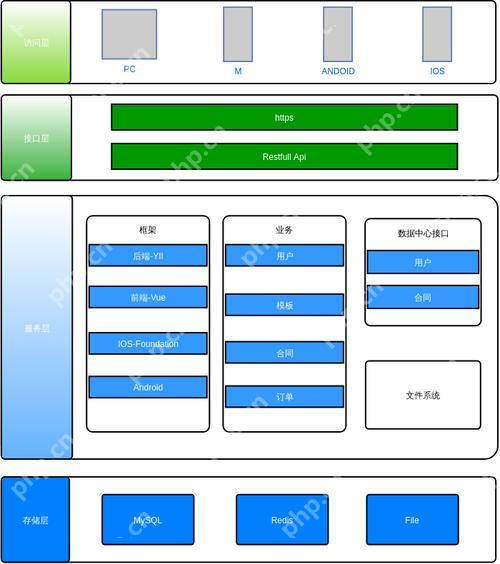
消息隊列(RabbitMQ/Kafka)集成方案
選擇消息隊列時,rabbitmq適合需要靈活路由和可靠傳遞的系統,而kafka適用于處理大量數據流并要求數據持久化和順序性的場景。1) rabbitmq在電商項目中用于異步處理訂單和庫存,提高響應速度和穩...

Kafka消息順序性如何在Linux上保障
在Linux環境下,確保Kafka消息順序交付,需要采取多種策略協同工作。以下方法能有效提升消息順序性: 分區策略:確保消息有序的關鍵 唯一分區鍵: 為每條消息分配一個唯一的鍵值(例如,訂單ID或...
Kafka分區策略在Linux上如何選擇
在linux上選擇kafka分區策略時,需要考慮多個因素,包括生產者和消費者的需求、數據特性、集群規模等。以下是一些常見的分區策略及其適用場景: Kafka分區策略 DefaultPartitioner:這是Kafka的...

Linux Kafka的運維管理有哪些挑戰
Linux Kafka的運維管理面臨著多個挑戰,主要包括以下幾個方面: 硬件與資源管理 硬件性能要求高: Kafka對CPU、內存和磁盤I/O有較高要求。 需要監控和優化硬件資源以避免瓶頸。 存儲擴展性: Ka...