
據(jù)")


排序

Python中如何使用seaborn庫?
在python中使用seaborn庫需要以下步驟:1. 安裝seaborn,使用命令pip install seaborn。2. 導入必要的庫,如seaborn、matplotlib和pandas。3. 創(chuàng)建或加載數(shù)據(jù),并將其整理成pandas數(shù)據(jù)框。4. 使...

怎樣在Python中處理Excel文件?
在python中處理excel文件可以使用openpyxl和pandas庫。1. 使用pandas讀取excel文件:df = pd.read_excel('example.xlsx', sheet_name='sheet1')。2. 使用openpyxl創(chuàng)建新excel文件:wb = workboo...
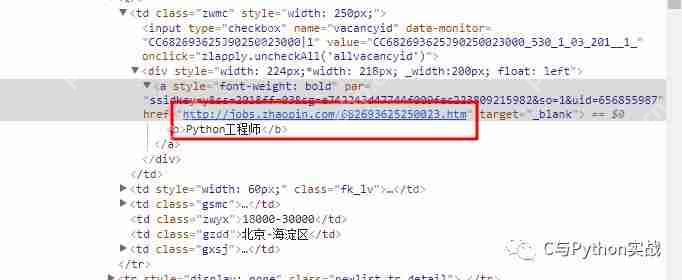
Python爬蟲之六:智聯(lián)招聘進階版
運行平臺: windows python版本: python3.6 ide: sublime text 其他工具: chrome瀏覽器0、寫在前面的話本文是基于基礎版上做的修改,如果沒有閱讀基礎版,請移步 Python爬蟲之五:抓取智聯(lián)招...

Python中如何遍歷目錄文件?
在python中,可以使用os.walk()和os.scandir()遍歷目錄文件。1.os.walk()適用于一般遍歷,可結合條件過濾文件。2.os.scandir()更適合大規(guī)模目錄的高效遍歷。 在Python中遍歷目錄文件是個常見的...

Python人馬獸系列是啥 Python人馬獸系系列主要內(nèi)容有哪些
“Python 人馬獸系列”沒有確切定義,可能與神話、游戲、庫戲稱、教育資源或拼寫錯誤有關。以下是可能相關的Python庫:1. NumPy/SciPy用于科學計算,2. Matplotlib/Seaborn用于數(shù)據(jù)可視化,3. S...

如何在Python中實現(xiàn)排序操作?
python中有多種排序方法:1. 使用sort()方法直接在原列表上排序。2. 使用sorted()函數(shù)返回一個新的排序列表。3. 通過key參數(shù)自定義排序邏輯。4. 使用第三方庫如pandas對大數(shù)據(jù)進行高效排序。5. ...

怎樣在Python中實現(xiàn)數(shù)據(jù)清洗?
在python中實現(xiàn)數(shù)據(jù)清洗可以通過以下步驟:1) 使用pandas的fillna方法處理缺失值,2) 用duplicated和drop_duplicates方法處理重復數(shù)據(jù),3) 利用pd.to_datetime方法格式化日期數(shù)據(jù),4) 通過iqr方...

Python中如何使用聚合函數(shù)?
在python中使用聚合函數(shù)可以通過內(nèi)置函數(shù)、numpy和pandas實現(xiàn):1)使用內(nèi)置函數(shù)如sum()、max()、min()處理簡單數(shù)據(jù);2)numpy提供高效的向量化操作,如np.sum()、np.mean()等;3)pandas適合復雜數(shù)...

Python中如何實現(xiàn)機器學習模型?
在python中實現(xiàn)機器學習模型可以通過以下步驟進行:1) 數(shù)據(jù)預處理,使用pandas進行數(shù)據(jù)清洗和標準化;2) 特征工程,利用rfe選擇重要特征;3) 模型選擇和訓練,使用scikit-learn庫實現(xiàn)線性回歸和...

Python中如何合并多個DataFrame?
在python中,可以使用pandas庫的concat和merge函數(shù)來合并多個dataframe。1)使用concat函數(shù)進行縱向或橫向拼接,適用于結構相同的dataframe。2)使用merge函數(shù)基于鍵進行合并,適用于需要靈活合...

怎樣在Python中實現(xiàn)多表關聯(lián)查詢?
在python中實現(xiàn)多表關聯(lián)查詢可以通過sqlalchemy來實現(xiàn)。1)安裝sqlalchemy并定義模型類和關系;2)建立數(shù)據(jù)庫連接并執(zhí)行查詢;3)處理查詢結果。使用sqlalchemy可以提高代碼可讀性和靈活性,但需注...